What is the Dirichlet Process 🌱
A Dirichlet distribution is a distribution over probability vectors based on some parameters. What if we want those parameters to be random?
- A Dirichlet Process is basically a distribution over distributions of parameters
Dirichlet Distribution
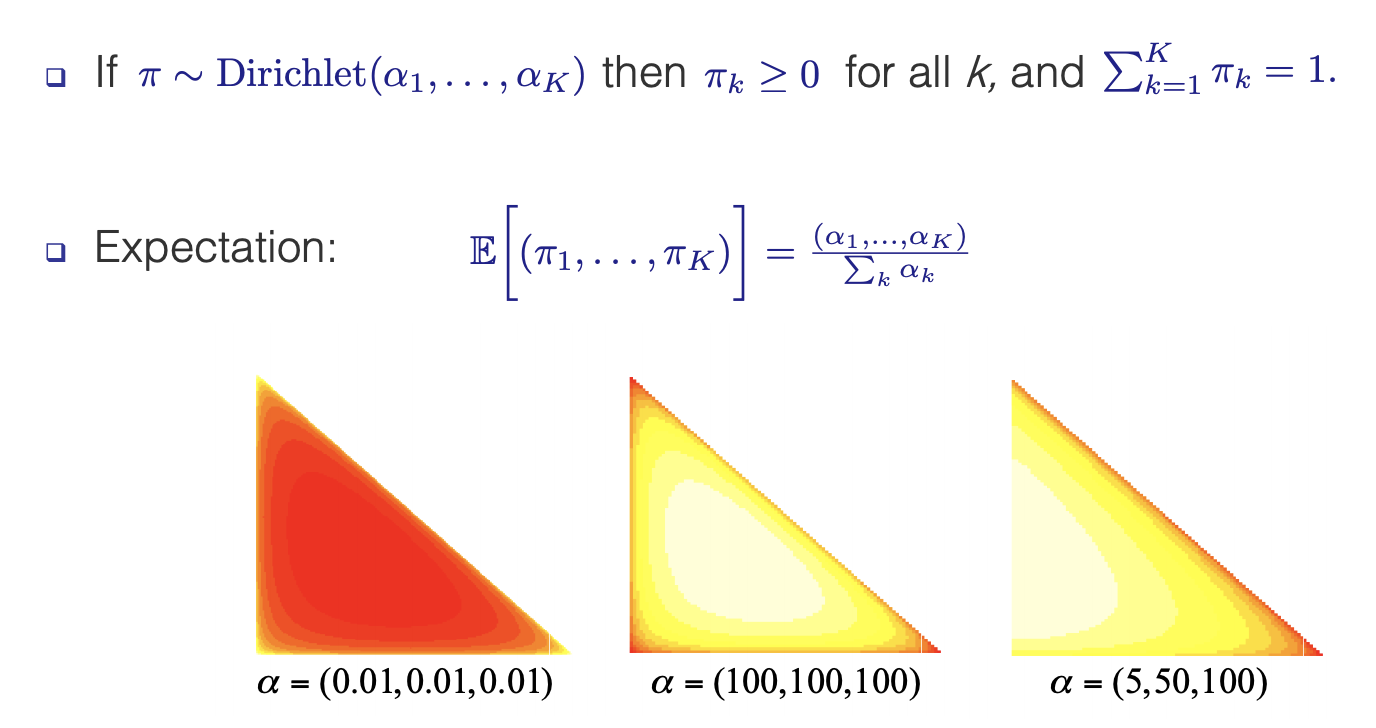
- A Dirichlet distribution is often used to probabilistically categorize events among several categories. Suppose that weather events take a Dirichlet distribution. We might then think that tomorrow’s weather has probability of being sunny equal to 0.25, probability of rain equal to 0.5, and probability of snow equal to 0.25. Collecting these values in a vector creates a vector of probabilities.
- The Dirichlet distribution is a distribution over positive vectors that sum to one (probabilities).
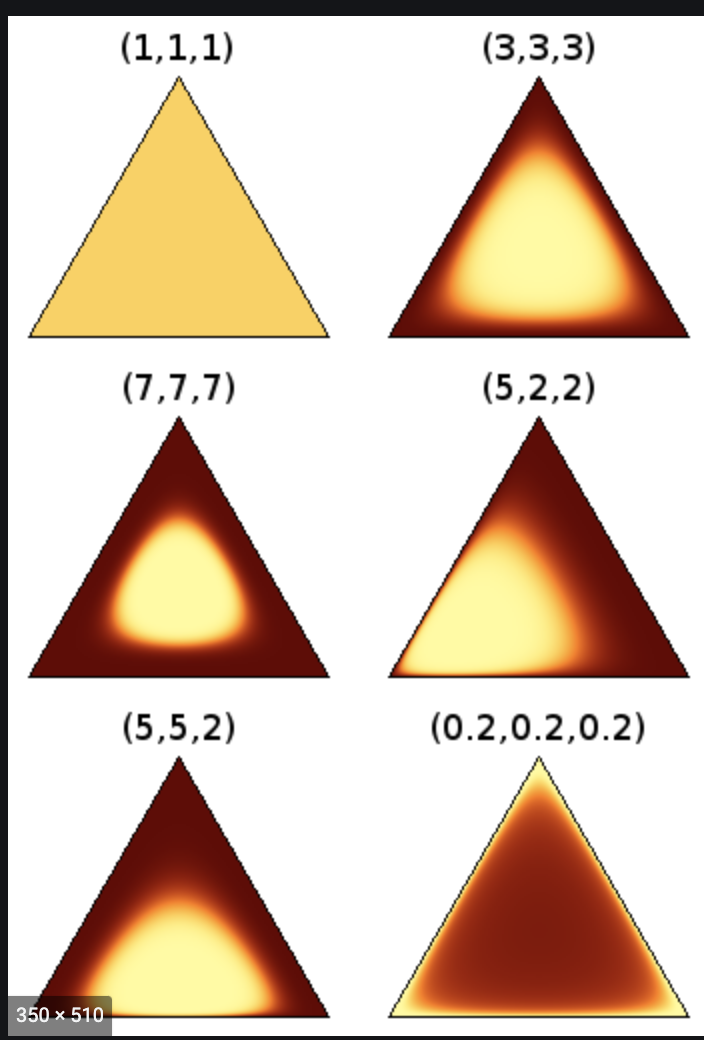
- Below shows what Dirichlet distributions with different parameters look like:
 |
 |
|---|---|
Relation to Beta Distribution
- A beta distribution is often used to describe a distribution of probabilities of dichotomous events, so it’s restricted to the unit interval.
- For example, for a Bernoulli trial, there is only a parameter \(\theta\) describing the probability of a “success.” Often we think of \(\theta\) as being fixed, but if we are uncertain about the “true” value of \(\theta\), we could think about a distribution of all possible \(\theta\)s, with a larger likelihood for those we consider more plausible, so perhaps \(\theta \sim B(\alpha,\beta)\), where \(\alpha>\beta\) concentrates more of the mass near 1 and \(\beta>\alpha\) concentrates more of the mass near 0.
- Extending the beta distribution into three or more categories gives us the Dirichlet distribution
Defining the Dirichlet Process
\[\quad G \sim \mathrm{DP}(\alpha, H)\]Definition 1
Let \(H\) be a distribution on some space \(\Omega\) (e.g. a Gaussian distribution on the real line) with the following known:
\[\pi \sim \lim_{K \rightarrow \infty} \operatorname{Dirichlet}\left(\frac{\alpha}{K} \cdots, \frac{\alpha}{K}\right)\] \[\text{ for } k=1, \ldots \infty \text{ let } \theta_{k} \sim H\]Then
\[G(\theta)=\sum_{k=1}^{\infty} \pi_{k} \delta_{\theta_{k}}(\theta) \text{ is an infinite distribution over } H \text{ and } G \sim \mathrm{DP}(\alpha, H)\]where \(\delta_{\theta_k}\) is the indicator which is zero everywhere except for $\delta_{\theta_k}(\theta_k) = 1$$
Definition 2
A Dirichlet process is the unique distribution over probability distributions on some space \(\Omega\), such that for any finite partition \(A_1,…,A_K\) of \(\Omega\). So if \(P \sim DP(\alpha,H)\) then:
\[\left(P\left(A_{1}\right), \ldots, P\left(A_{K}\right)\right) \sim \operatorname{Dirichlet}\left(\alpha H\left(A_{1}\right), \ldots, \alpha H\left(A_{K}\right)\right)\]Relating to the Chinese Restaurant Process
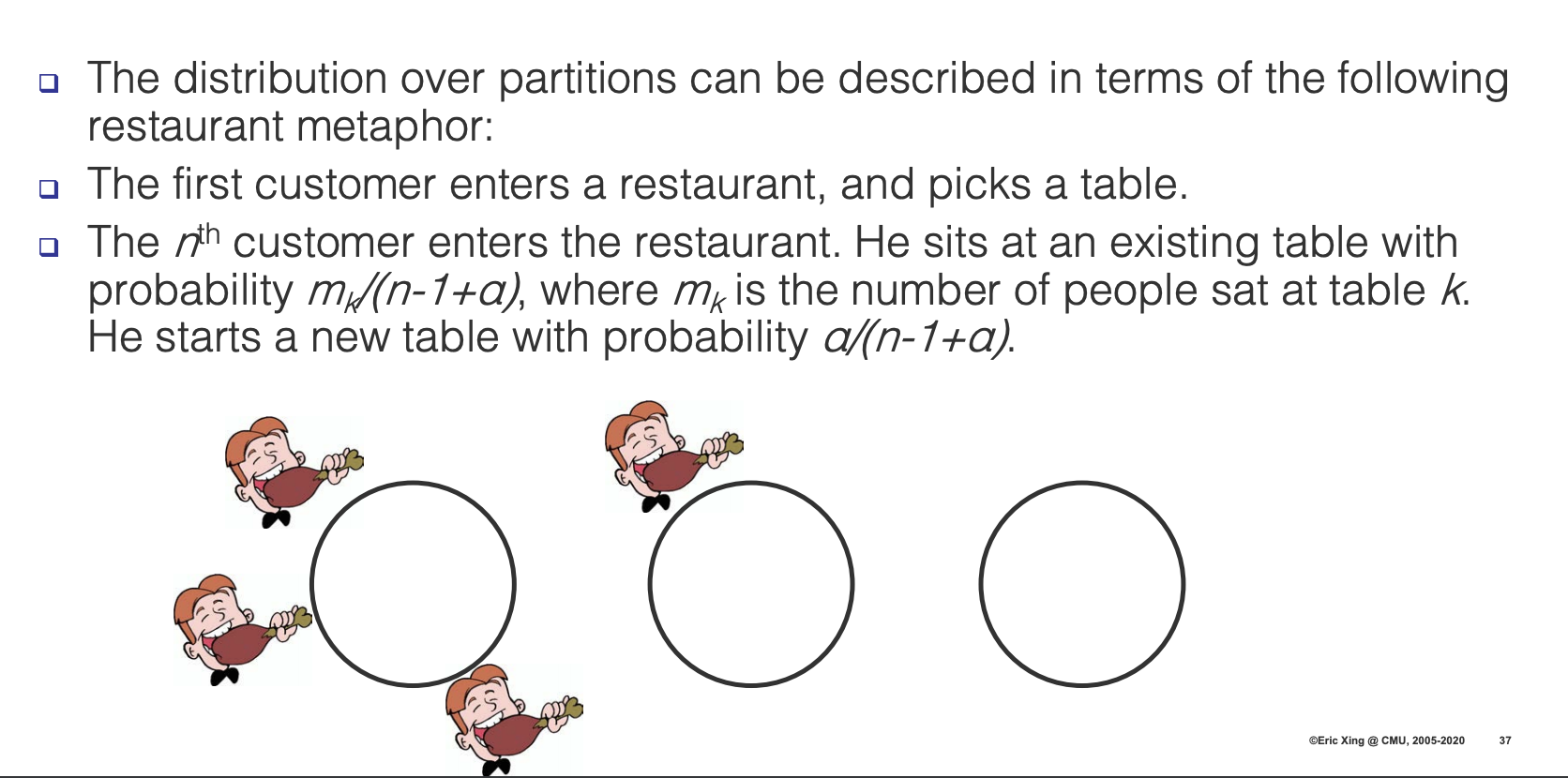
- Each partition \(A_1,…,A_K\) represents a table at the restaurant
- \(P(A_i)\) is the probability mass of customers on table \(i\) (e.g. \(n_i/N\))
- \(H(A_i)\) is a draw from the base measure \(H\) for the corresponding table \(A_i\). This could act as the label for a table.
This could also be explained with the Polya Urn Process which is basically identical except that each \(A_i\) represents a color, with \(H(A_i)\) as a base measure from the color and \(P(A_i)\) as the probability mass of that specific color
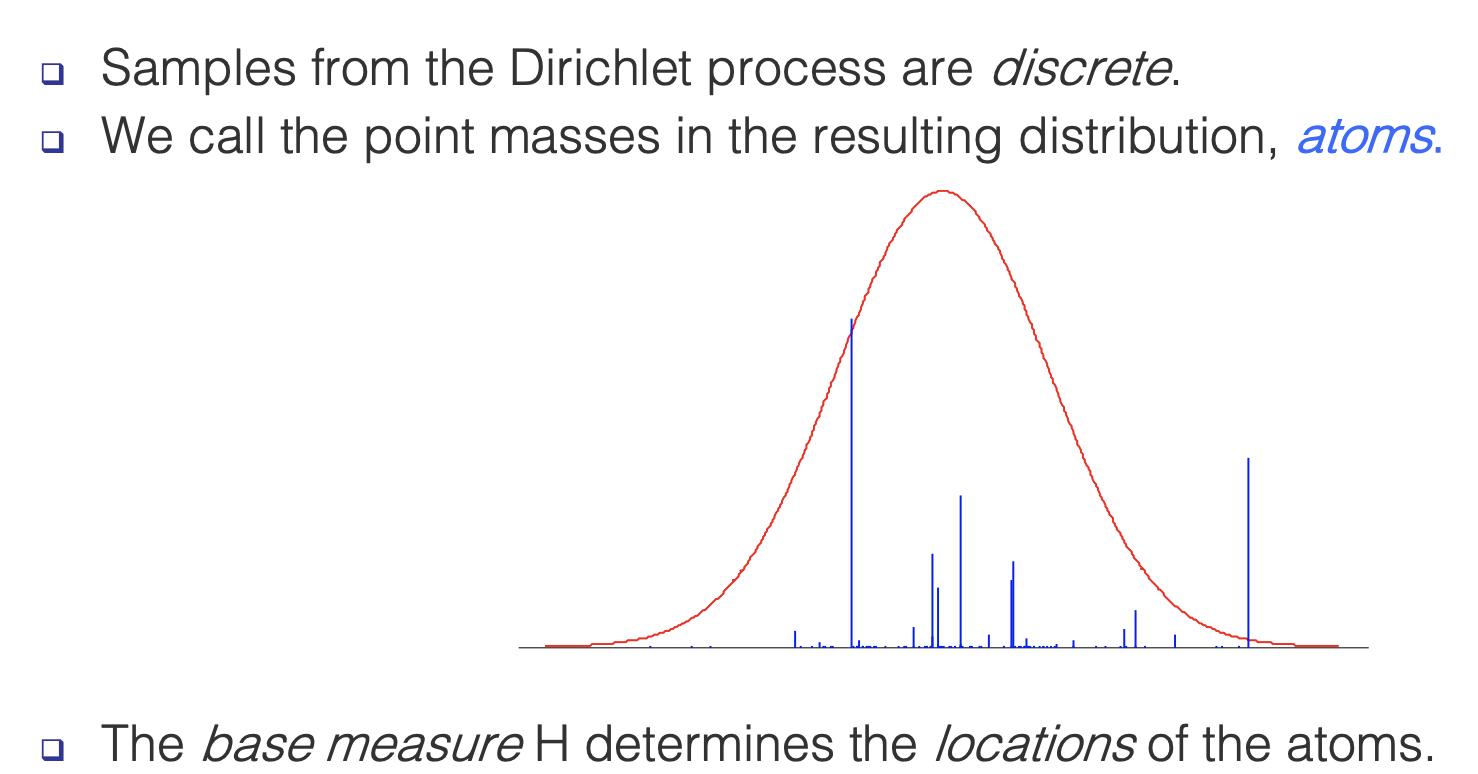
Sampling from the DP
 |
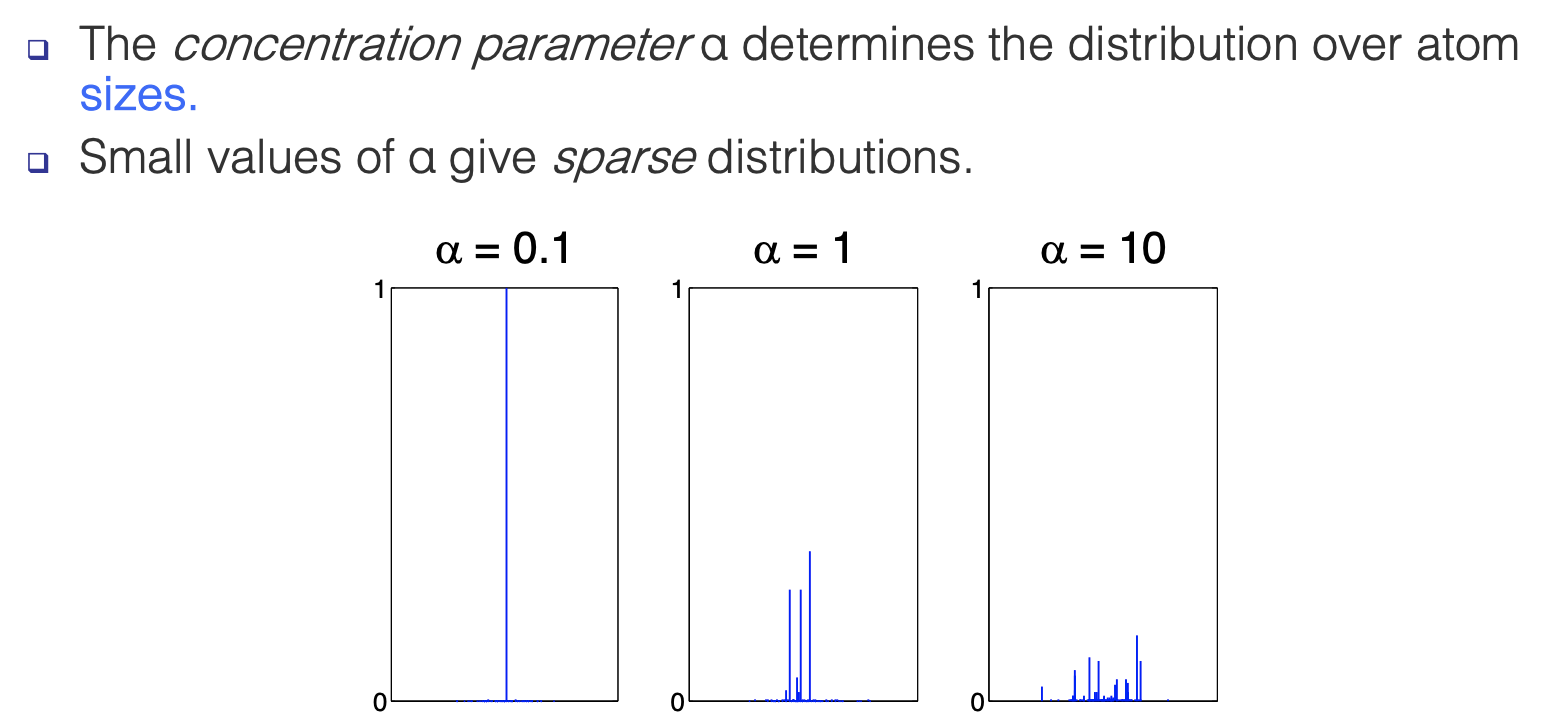 |
|---|---|
| The base measure \(H\) does not influence the probability of a point joining that atom/class, it only influences the locations of the atoms (the value of the class) as shown in the graph above. | These properties of alpha are true because this means that a new value is less likely to take on a new class value with a small alpha (see predictive distribution below) |
Predictive Distribution
A new data point can either join an existing cluster, or start a new cluster. What is the predictive distribution for a new data point?

Hierarchical Dirichlet Process/Chinese restaurant franchise
Notes mentioning this note
There are no notes linking to this note.